<畳み込みもAttentionも使わない新たな画像処理のスタンダードとなるか!?【MLP-Mixer: An all-MLP Architecture for Vision】>
画像処理のニューラルネットワークと言えば、誰もが思い浮かべるのは畳み込み層を使ったモデルだと思います。最近ではAttentionを使ったモデルも出てきており、基本的なMLP(Multi Layer perceptron)のみを使用したモデルが使われることはないというのが最近の主流となっています。その中で、今回紹介する論文では畳み込み層もAttentionを使ったモデルも使用せず、MLPのみを使用したシンプルなモデルで同等の精度を実現しています。
これは今後の画像分野の研究に一石を投じるような内容だと考えられ、畳み込みと組み合わせることで画像分野において更なる発展が期待されます。
◆何をしたのか
冒頭でも述べましたが、現状画像分野で主流となっている畳み込み層やAttentionを使用せず、MLPのみを使用してそれらを使用したモデルと同等レベルの精度を達成するモデルの提案がされています。
◆提案されているモデルの概要
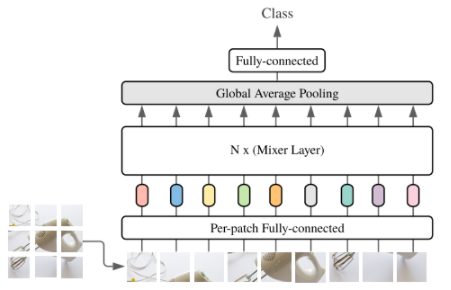
図1 モデルの全体像
図1は提案されているモデルの全体像です。今回のモデルで特徴的な部分としては、「Mixer layer」の部分です。このMixer layerについて少し詳細に見ていきたいと思います。かなりシンプルなため、説明もすぐに終わります。
図2にMixer layerの概要を示してあります。Mixer layerは以下の二つの要素から成り立っています。
- Token mixing: channelごとの処理を行う(MLP1)
- Channel mixing:Token mixingで生成されたChannelごとの特徴量について処理を行う(MLP2)
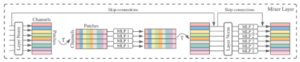
図2 Mixer layer
①でやっていることはMLPを使ってchannelごとに特徴量を生成しています。一方②でやっていることはMLPを使って、画像を分割したpatchごとに特徴量を生成しています。やっている処理の内容としては以上となり、非常にシンプルなモデルであると言えると思います。
提案モデルについて少し考察ですが、画像を分割して縦横方向とチャンネル方向について処理をしていることから、基本的な構造としては疎な畳み込み処理とみなすことができると考えられます。著者もその部分には言及しており、特殊なパターン(1x1の畳み込みなど)と同じ処理をしているとみなすことができるが、特徴量抽出の結果は異なると述べられています。理由については特に記載はないため、今後このあたりの研究が進むと画像処理の発展につながる可能性があるのではないかと考えられます。
◆モデルの評価
表1 モデルの評価
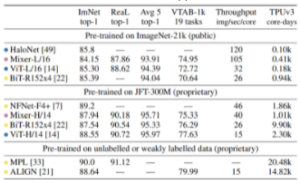
表1にモデルの評価結果を示しています。特筆すべき点としてMixer-H/14(画像を14×14に区切ったもの)は他の最新のモデルとそん色ない精度を出している上に事前の学習にかかる時間が約2倍以上も短くなっています。画像を区切る大きさの設定等、ユーザで決定するハイパーパラメータの影響は大きい可能性が高いですが、それに関しては畳み込みを使用した場合にも同じことがいえるため、大きな問題ではないと考えられます。
◆まとめ
MLP-MixerはMLPのみを使って、画像処理について畳み込みやAttentionを使用したモデルとそん色ない結果を出しています。更に、シンプルな構造であるがゆえに、学習時間が短縮される可能性を大いに秘めています。近年は画像処理といえば畳み込み、Attentionで進んできた大きな流れに一石を投じる内容となると考えられます。今後Mixerモデルについて考察が進むことによって、画像処理分野に新たな流れができる可能性に期待しようかと思います。
<参考文献>
1.MLP-Mixer: An all-MLP Architecture for Vision (https://arxiv.org/pdf/2105.01601v1.pdf)
EVENTS


