4/20 代表通信~これであなたもKagglerに!PyCaretに関して

こんばんは。代表の草場です。
本日は嫁の味噌ラーメンを食べて一日開始。卵も入っていました。おいしく一日が始まりました。
今回は、趣向を変えて、PyCaretというライブラリの紹介をします。やじろべえさんの「機械学習の自動化ライブラリ「PyCaret」を使ってみた」を参考にしています。
世界最大のデータコンペ、Kaggle。Kaggleへの挑戦を始めたものの、挫折するケースが多いです。シンラボにはKaggle部があるので、私は継続できています。継続しづらい理由の一つが、すぐに結果にならない点かなと。そこで、自分もデータ解析の自動化ツールなど探していましたが、一つの選択肢はDataRobotです。現在はCOVID-19解析用に、無料公開もされています。金額が、、ということで、なかなか使えていませんでした。他のみGoogleのAutoMLとか。
ここで発見したのが、PyCaretです。Google Colaboratoryを使って、タイタニックのデータでとりあえず試してみました。とりあえず、
pip install pycaret
でインストール。タイタニックのtraining dataをまず読み込みます。通常はこの後に、フィーチャーエンジニアリングという特徴量いじりをやる形です。ここを自動化してくれるのが、PyCaretです。
以下の前処理をやってくれる形。
![]()
タイタニックデータは分類問題のため、PyCaretのclassification関数を使います。setup関数を使って、前処理。setup関数の引数に目的変数がどの列にあるかを指定し、使いたくない列がある場合はignore_featuresでリストに渡してあげます。
from pycaret.classification import *
exp1 = setup(df, target = ‘Survived’, ignore_feature=[‘PassengerId]
実行後、以下のような結果がでます(一部)
| Description | value | |
| 0 | session_id | 8260 |
| 1 | Target Type | Binary |
| 2 | Label Encoded | None |
| 3 | Original Data | (891, 12) |
| 4 | Missing Values | True |
さて、モデルの作成と結果を見たい場合が以下のコードです。
compare_models()
すると、以下の結果(一部)
| Model | Accuracy | AUC | Recall | Prec. | F1 | |
| 0 | Decision Tree Classifier | 0.834800 | 0.813200 | 0.719900 | 0.828500 | 0.769800 |
| 1 | CatBoost Classifier | .834700 | 0.876000 | 0.677900 | 0.867400 | 0.759500 |
| 2 | Extreme Gradient Boosting | 0.823600 | 0.869700 | 0.698600 | 0.822900 | 0.753200 |
| 3 | Ridge Classifier | 0.821900 | 0.000000 | 0.740400 | 0.785600 | 0.761000 |
| 4 | Logistic Regression | 0.820300 | 0.868200 | 0.732100 | 0.790400 | 0.756700 |
| 5 | Gradient Boosting Classifier | 0.818700 | 0.857800 | 0.669400 | 0.831100 | 0.739700 |
| 6 | Extra Trees Classifier | 0.815500 | 0.858300 | 0.685500 | 0.817800 | 0.739400 |
さらに、アンサンブル、スタッキングもやってくれます(省略)。便利だー。
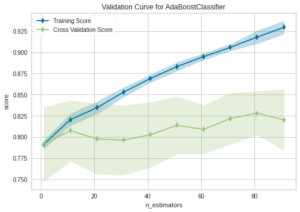
可視化は以下のコード。
adaboost = create_model(‘ada’)
plot_model(adaboost, plot=’auc’)
今後も使った結果を掲載していきます!
EVENTS


