今だからこそ知りたいビッグデータ×AI(第2回)

※本記事は、未来技術推進協会ホームページにて2018年7月21日に掲載されたものです。
こんにちは。cygnusです。
前回の記事では、ビッグデータがどのようなものか、世界でのデータ利用情勢を踏まえた背景、そこから受けられる恩恵の例を説明しました。
第2回となる今回は、様々な場所に存在し蓄積された膨大なデータ、それらのデータをネットワークに繋げて利用することに伴う、越えるべき壁を説明します。
目次
超えるべき壁
前回記事の「消費と生活への変革」で取り上げましたが、我々が普段オンラインや実店舗で購買する際に、いつどこで何を買ったか、性別・年齢・利用頻度などの情報がほぼリアルタイムに蓄積されて行くことになります。
これを趣味趣向によるレコメンデーションやサプライチェーン管理などに活かすのはプラスの側面ですが、マイナスの側面に目を向けると、我々の生活が丸裸に色なること考えられます。
また、ビッグデータの優位性を支えるものとして、個別なデータ同士をリンクさせて、一つの観点では気づかない傾向や価値を抽出できることがあげられます。
例えば、消費の履歴データと位置情報による移動経路データをリンクさせることで、経路上にあるお店や施設のデータをレコメンドしたり、活動拠点の周辺で価格面・品質面で優位なお店やそこへの経路をお知らせするなどが可能になります。
データ同士がリンクできるように、データの二次利用をすることがビッグデータの本来の威力を発揮するために必要となりますが、二次利用の範囲によって情報漏えいや悪用のリスクも高まっていきます。
個人の趣味や思想、住居や家族構成・人間関係、ライフステージの変化などがほぼ自動的に捕捉されるとしたら、「プライバシー」が侵害される可能性も否定はできません。
個人の生体情報や診療履歴、DNA分析情報など、個人にあわせた最適な医療提供や医療業界の進化につながるものも、意図しない第三者に渡ってしまうことも考えられます。
扱うデータが各個人に深く関わるものになればなるほど、悪用や意図しない使われ方をした場合の影響は大きくなり、便利さとプライバシーのトレードオフという、長年議論されては形を変えて来た問題に対処していくことが必要となってきます。
このような問題に対して取られる対策について説明します。
匿名化と告知・同意
個人のデータを扱う際の保護対策として「匿名化」と「告知・同意」のそれぞれについて、概要と技術的な側面をご紹介します。
匿名化
ビッグデータ活用の際に、集合としての傾向を把握できれば十分である場合、個人を特定できる情報(氏名や住所、電話番号や顔の画像データや音声データなど)をマスクしたりスクランブルすることで匿名化することは有効であるといえます。
マスクはデータが読み取れないように隠すこと、スクランブルは元のデータがわからないように変換することを指します。極端な話、同じ傾向を持つ複数名の個人がいたとしても、それぞれを特定する必要はなく、あくまで全員に同様の情報を提供することで目的は達成できます。
逆に匿名化をしすぎると、本来そのデータの持つ特徴が失われ、分析対象として価値の低いデータになってしまうため、価値を保持したままプライバシーを守るというバランスを考えることが重要です。
匿名化により個人特定を難しくする技術には、大手企業でも採用され研究も盛んに行われている「k-匿名化」や、AppleがiOS 10で採用していることで一躍有名となった「差分プライバシー」といった技術があります。各々の技術的な解説は参考記事に譲ります。
このように、個別なデータに対して個人情報を守るために匿名化が活用されており、日々技術の改善が行われています。
次に、データをリンクさせて扱う場合など、二次利用も含めたデータの保護に採用されている「告知・同意」について説明します。
告知・同意
ビッグデータは、主に「データ取得/収集」→「データ分析/価値づけ」→「データ利用」といった流れで活用しますが、このデータ収集には、企業や機関が個人からデータを収集する、企業や機関同士でのデータ提供により収集するという2種類があります。
この際に、そもそもデータを収集して良いか、収集したデータをどの範囲で利用するか、第三者へ提供して良いかといった情報を個人に告知し、同意を得たうえで活用していくことが重要となります。
文書で明示し同意の取り決めを得ること、メールなど証跡が残る形で告知し拒否の連絡がないことで同意したとみなすことなど、お互いの負荷を減らしながら運用がなされています。
許可なく第三者に提供したり、同意を得た範囲を超えて活用していたことで、法的な措置がとられた例も存在しています。
合意が得られていることで一定の効力はありますが、膨大な告知文を理解した上で同意しているか、取り決めた範囲で利用していることにリスクはないのか、など、完全に保護ができるわけではないという課題はあります。
活用を踏まえた法整備
個人情報を守りつつ、ビッグデータの恩恵を引き出すため、産業界や学術界の発展も踏まえて平成29年5月に整備されたのが改正個人情報保護法です。詳細は割愛しますが、押さえておきたいポイントをご紹介します。
改正個人情報保護法の中で重要なポイントは、「匿名加工情報:特定の個人を識別することができないように個人情報を加工した情報」であれば、第三者に提供する場合に本人の同意が不要になる、といえます。
先に紹介した匿名化の技術を活用することで、本人を識別可能な情報を排除する、あるいは復元できない加工を施すことが必要です。
第三者提供が可能となる代わりに、情報取扱事業者、利用事業者の双方は以下のようなことを守る必要があります。
情報取扱事業者
- 適正な加工方法に基づき加工すること
- 加工方法自体を安全に管理すること
- 第三者へ提供する情報項目と提供方法を公表すること
利用事業者
- 加工方法の取得は禁止すること
- 本人の再識別は禁止すること
- 第三者へ提供する情報項目と提供方法を公表すること
このように適切に規定・管理することで、ビッグデータが持つ潜在的な価値を引き出していく流れになってきています。こうした動きは日本でも着々と進んでいますが、欧州での法整備も学ぶところが多いです。
欧州データ保護観察局(EDPS:European Data Protection Supervisor)が主導して、「プライバシー・バイ・デザイン」の概念を提唱し、「Big Data VS Privacy」から「Big Data with Privacy」へのシフトを推進しています。
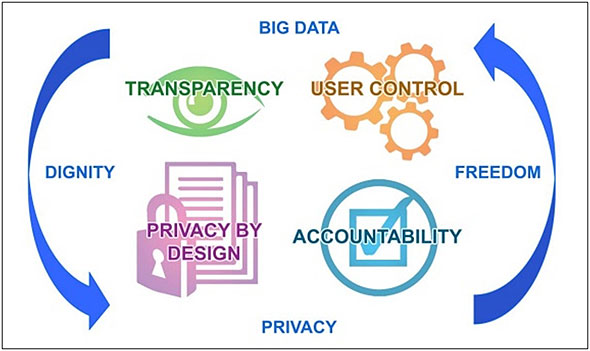
ビッグデータとプライバシーの関係(出典:European Data Protection Supervisor「Meeting the challenges of big data」)
こちらの「プライバシー・バイ・デザイン」については、次回の記事で触れていきたいと思います。
総括
今回は、ビッグデータを活用していくうえで超えていくべき壁とその実情・対策方法についてご紹介してきました。
便利なものには負の側面がつきものですが、実現したい未来を描き、そこに向けて様々な対応策を講じ、バランスを取っていくことでもっと豊かな世の中になっていくと考えています。
ただ、日本では個人情報の利用に批判的な声も多いのが実情で、法整備に加えて感情面の障壁も超える必要があるでしょう。
次回は、欧州での法整備について触れつつ、プライバシー・バイ・デザインを始めとする、技術的なアプローチについて紹介する予定です。
参考
EVENTS


