5/16 代表勉強通信~PyCaretで異常検出

こんばんは。代表の草場です。
PyCaretで遊ぼう第四回です。昨日のDocker Toolkitをインストールできない問題は解決せずです。本日は、「Build your first Anomaly Detector in Power BI using PyCaret」を取り上げます。この記事で取り上げられているのは以下です。
異常検知とは?
Power BI で教師なしの異常検出器をトレーニングして実装
結果を分析し、ダッシュボードで情報を視覚化
Power BI 本番環境で異常検知器を導入するには?
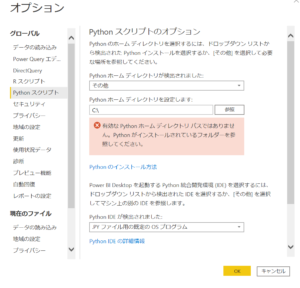
前々回の記事同様、仮想環境で実施するのでAnacondaインストール推奨、そしてMicrosoftのPower BIデスクトップはインストールしておいてください。仮想環境上でPyCaretをインストール。そしてPower BIと仮想環境とリンクさせます。Power BI→ファイル→オプションと設定→オプション→Pythonスクリプトで、参照から仮想環境のパスを指定します。
■異常検出とは?
異常検出は、データの中で異常なふるまいをするアイテム、イベント等を識別するために使用される機械学習のテクニックです。銀行詐欺、構造的欠陥、医療問題などに使われます。
この記事で取り上げられている異常検出器を実装する方法は以下の3つです。
(a) 教師あり学習。データセットに、どのトランザクションが異常で、どのトランザクションが正常であるかを識別するラベルがある場合に使用されます。
(b) 半教師あり。正常なデータのみでモデルを訓練することです。その後、訓練されたモデルのデータの分布に基づいて新しいデータ点を使用し、そのデータが正常かどうかを予測することができます。
(c) 教師なし。モデルを完全なデータセットで訓練し、インスタンスの大部分が正常であると仮定します。残りのインスタンスの中で最も適合していないと思われるインスタンスを探します。
この記事では、PyCaretを使用して、教師なし異常検出をPower BIに実装することについて説明されています。
■目的
業務上の購買管理を効率的に行うために従業員に法人クレジットカードを発行している企業を想定します。この記事では、米国デラウェア州の教育省の2014年から2019年までの州職員のクレジットカード取引を使用します。ここから異常検出をします。データは以下です。
https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/delaware_anomaly.csv
Power BIで、ファイル→データを取得→Web、で上記のURLを打ち込みます。
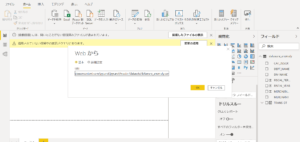
こんな感じのデータです。読み込みをクリック。
■モデルのトレーニング
これは先日書いた記事と同じプロセスです。データの読み込み後、Power BIで「データの読み込み」をクリック。すると、Power Query Editorが起動します。 変換 → Pythonスクリプトを実行する、で以下のコード実行します。なんて簡単なんだ。
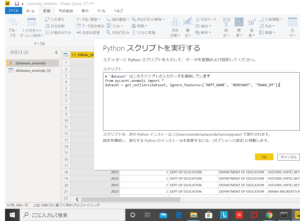
from pycaret.anomaly import *
dataset = get_outliers(dataset, ignore_features=[‘DEPT_NAME’, ‘MERCHANT’, ‘TRANS_DT’])
ignore_featuresで、いくつかの列を無視。どの部署か、どこで発注したか、取引の日付は無視します(日付は大事な気が、、、)。PyCaretには、10以上の異常検出アルゴリズムがあります。デフォルトでは、K-Nearest Neighbors Anomaly Detector を 5% の割合で学習します。自分のPCの性能が悪いのか、20分程度時間がかかりました。
2つの新しい列が追加されました。label(1 = 異常値、0 = 正常値)とscore(スコアが高いデータポイントは異常値として分類)です。クエリを適用して、Power BI データ セットで結果を確認します。この図の作成法がまだわからず。Power BI、もっと勉強します。。。取り急ぎ、PyCaret公式GitHubのこれをダウンロード。以下のきれいな図が出ます。


取引量に対する異常値は比較的小さいですが、取引金額に対する異常値は多いですね(47%)。
■本番環境での異常検知の実装
さて、上記の方法では、Power BI のデータセットがリフレッシュされるたびに異常検出器をトレーニングしていますが、これは2つの理由で問題になるます。
1.モデルを新しいデータで再訓練すると、異常値のラベルが変更されることがある
2.モデルを再トレーニングするために時間がかかる
本番での使用を想定している場合の代替方法は、事前にトレーニングしたモデルをPower BIに渡してラベリングをおこなうことです。先日の記事にも記載しましたが、適当なエディタ(自分はJupyter Notebook)を使って異常検出モデルを学習します。その後、pklファイルで保存。以下、コードです。
import pandas as pd
data = pd.read_csv(“delaware_anomaly.csv”)
from pycaret.anomaly import *
ano1 = setup(data, ignore_features=[‘DEPT_NAME’, ‘MERCHANT’, ‘TRANS_DT’])
knn = create_model(“knn”)
save_model(knn, ‘pklファイルを保存するパスを指定’)
この事前にトレーニングしたモデルを使って、予測をします。
本日は気力が途切れたのでまた明日!
EVENTS


