6/14 代表通信~「Building Machine Learning Powered Applications」再び

こんばんは。代表の草場です。
「Building Machine Learning Powered Applications: Going from Idea to Product 1st Edition」、再びです。4章で詰まっていました。StackExchangeのwriteコミュニティーから、質問と回答(XMLファイル)を取り出してきて、これをベースのデータとしてモデルを構築していくのですが、そのデータの取得、前処理部分でウンウンうなっていました。
まずはこのDataDumpからXMLデータを取得してきてrawタグを取り出してきます。XMLファイルを扱ったことがなく、まず詰まりました。CyberTechこんばんは。代表の草場です。
「Building Machine Learning Powered Applications: Going from Idea to Product 1st Edition」、再びです。4章で詰まっていました。StackExchangeのwriteコミュニティーから、質問と回答(XMLファイル)を取り出してきて、これをベースのデータとしてモデルを構築していくのですが、そのデータの取得、前処理部分でウンウンうなっていました。Stack Exchangeは、哲学やゲームなどのテーマに焦点を当てた質問応答サイトのネットワークです。DataDumpには多くのアーカイブがあり、Stack Exchangeネットワーク内の各ウェブサイトごとに1つずつあります。
まずはこのDataDumpからXMLデータを取得してきてrowタグを取り出してきます。XMLファイルを扱ったことがなく、まず詰まりました。XMLファイルの関してはCyberTechさんのこの記事を読み、そしてPython公式、しのやまさんのQiitaの記事を読んでPythonでのXMLファイルの使い方のお勉強。わかったようなわからんようなです。xml.etree.ElementTreeがカギなのね。使ったXMLファイルは以下です。
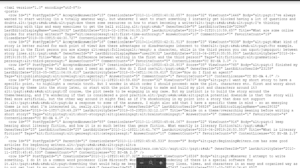
rowタグ部分に、必要な情報がつまっているので、
にて、rowタグ取り出し。以下のような情報が取り出されます。
BeautifulSoupを使ってBody部分をparseします。
最後に、
にて、DataFrame形式へ。と、ここで、本に書いてあるデータと実際にサイトから取ってきたデータが微妙に違うことに気付きました。本出版時から時間がたっているので当たり前か。
どのタイプの質問が高得点を獲得しているかを確認します。質問のスコアを真のラベルである質問の品質の弱いラベルとして使用したいからです。まず、問題を関連する回答にマッチさせます。次のコードは、受け入れられた回答を持つすべての問題を選択し、回答のテキストと結合します。最初の数行を見て、回答が質問と一致していることを確認することができます。これにより、テキストに素早く目を通し、その品質を判断することもできます。
今日はここまで。
EVENTS


