機械学習奮闘記③scikit-learnを利用した学習とモデル予測

みなさん、こんにちは
シンラボ広報部の福田です。
非テック系の福田による機械学習勉強日記です。
今日はscikit-learnを利用した学習とモデル予測をやってみます。
scikit-learnは、Pythonの機械学習ライブラリで、scikit-learnを使うにはAnacondaの開発環境のパッケージを使うと簡単です。また、Anacondaのインストール方法は前回の記事を参照ください。
1.「scikit-learn」のインストール(事前準備)
「Anaconda」を立ち上げて、「Environment」、「自分の設定環境(私の場合はTest1」を選択します。その後、「Not Instralled」を選んで、検索すると一覧で出てきます。そこで、「scikit-learn」にチェックを入れて、一番下の「Apply」を押すと、自動でインストールが行われます。
scikit-learnを用いて機械学習を行うときに、自分が行いたい分析(分類/回帰/クラスタリングなど)について、適切なモデルを選択する際の手助けとなるものです。
2. データの準備
早速、準備が整ったので、次は機械学習に使うデータを作ります。まずはお試しなので、なんでも良いです。
今回は下記の事例で予測モデルを作ってみました。
説明変数:Height:身長、Weight:体重
目的変数:JumpSkill:ジャンプ力/1=低、2=中、3=高
まずは、「Jupyter notebook]を開いたら、次の画面になります。ここで、右の方の「New」→「Text File」を選択します。

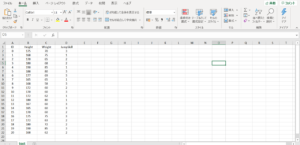
 ここで、テキストエディタに用いるデータ入力します。下記は練習用に20名分作りました。入力後に、名前を変更して保存します。今回は「200810_test.csv」としました。ファイルの保存先は、「Jupyter notebook]を起動するディレクトリ(私の設定ではC:\Users\fukud)に入れておきます。ここで、B列の「Height」とC列の「Weight」は説明変数、D列の「JumpSkill」は目的変数としています。
ここで、テキストエディタに用いるデータ入力します。下記は練習用に20名分作りました。入力後に、名前を変更して保存します。今回は「200810_test.csv」としました。ファイルの保存先は、「Jupyter notebook]を起動するディレクトリ(私の設定ではC:\Users\fukud)に入れておきます。ここで、B列の「Height」とC列の「Weight」は説明変数、D列の「JumpSkill」は目的変数としています。
次に、下記のPythonの画面でコマンドを入力して、「Shift」+「Enter」を押すと、csvファイルに入力した表が表示されます。また、「import pandas as pd」は必要なデータを読み込みコマンドです。
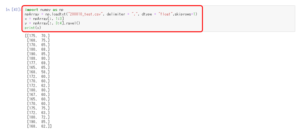
import pandas as pd
pd.read_csv(“200810_test.csv”)

後で使いたいので説明変数である「Height」と「Weight」の要素のセットを1次元配列を内包する2次元配列を作ってみます。下記のように入力すると、表示されます。
import numpy as np
npArray = np.loadtxt(“200810_test.csv”, delimiter = “,”, dtype = “float”,skiprows=1)
x = npArray[:, 1:3] y = npArray[:, 3:4].ravel()
print(x)

ここで、「y = npArray[:, 3:4].ravel()」は現時点では意味はないです。後で使いたいので、入力しただけです。内容としては、csvファイルの内容を読み込んで、従属変数の「JumpSkill」を要素とする1次元配列を作成します。また、「.ravel()」を用いたので、「print(x)」の代わりに「print(y)」に変更すると、元のnumpy配列オブジェクトの参照を利用して、下記の一次元配列が生成できます。

訓練データと評価データの準備
ここでは、先ほど読み込んだデータを訓練用と評価用に分割して用います。今回の計算では、訓練用データは70%、評価用データは30%としましたが、これは適宜変更できます。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
print(x_train)
print(y_train)
print(x_test)
print(y_test)
実行すると、下記のように表示されます。ここで、上の14個のデータが訓練用データ、下の6個が評価用データになります。「train_test_split(x, y, test_size=0.3)」の「0.3」を変更すれば、訓練用データの数は自由に調整できます。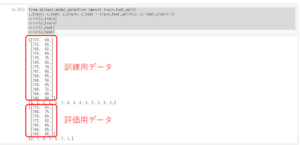
アルゴリズムの選択
今回は「決定木」を用いてみます。下記のように入力します。
from sklearn import tree
clf = tree.DecisionTreeClassifier()
学習
先ほどの訓練データ元に予測モデルを生成していきます。ここで、学習によるモデル精鋭には、全てのアルゴリズムにおいても、fit()関数を用います。
clf.fit(x_train, y_train)
予測
次に、評価用データを用いて予測を行います。ここでは、predict()関数を用います。
predict = clf.predict(x_test)
モデル評価
最後にモデル評価を行います。下記を実行すると、正解率が表示されます。ここで、正解率が高いほど精度の高いモデルになります。ただ、今回は元のデータが20しかないので28%です。
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, predict))
今回は正解率を求めずに、少ないデータで使い方を覚えるための練習台でした。大規模なデータを使えばもう少し厳密な評価ができます。
EVENTS


